
百度出席人工智能顶会AAAI2021 AI技术实力行业领先
- 2025-07-18 15:30:00
- aiadmin 原创
- 359
今天,环球人工智能顶会AAAI 2021以虚拟样子正在线召开,并于会前颁发了论文收录结果。AAAI 2021投稿论文总数到达“惊人的老手艺水准”,9034篇投稿论文中,7911篇领受评审,最终1692篇被考中,考中率为21%;百度再创佳绩,一举功劳24篇优质学术论文,涵盖盘算机视觉、自然发言管束、常识图谱、量子呆板研习等众个规模,出现出行业领先的AI手艺能力,同时这些手艺革新和冲破将有助于促进智能对话、智能办公、聪敏医疗、聪敏金融、智能交通等场景的落地使用,加快中邦智能经济时间的到来。
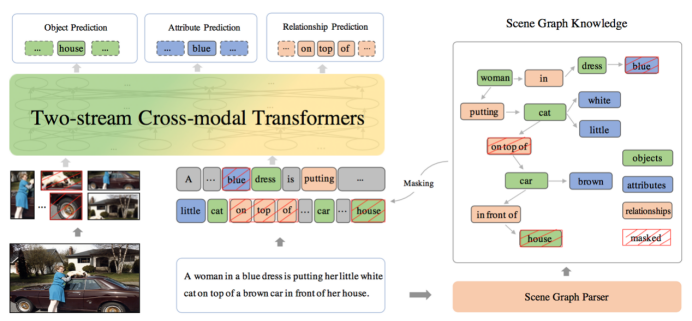
视觉-发言预操练的方向是通过对齐语料研习众模态的通用结合暗示,将各个模态之间的语义对齐信号交融到结合暗示中,从而提拔下逛职分后果。已有的视觉发言预操练法子正在预操练流程中没有分辨平淡词和语义词,学到的结合暗示无法描画模态间细粒度语义的对齐,如场景中物体(objects)、物体属性(attributes)、物体间相干(relationships)这些深度剖判场景所必备的细粒度语义。本文提出了常识巩固的视觉-发言预操练手艺ERNIE-ViL,将包蕴细粒度语义讯息的场景图先验常识融入预操练流程,创修了物体预测、属性预测、相干预测三个预操练职分,正在预操练流程中尤其眷注细粒度语义的跨模态对齐,从而研习到可能描画更好跨模态语义对齐讯息的结合暗示。动作业界首个融入场景图常识的视觉发言预操练模子,ERNIE-ViL正在视觉问答、视觉常识推理、援用外达式剖判、跨模态文本检索、跨模态图像检索等5个众模态类型职分上获得了SOTA后果,同时,正在视觉常识推理VCR榜单上获得第一。
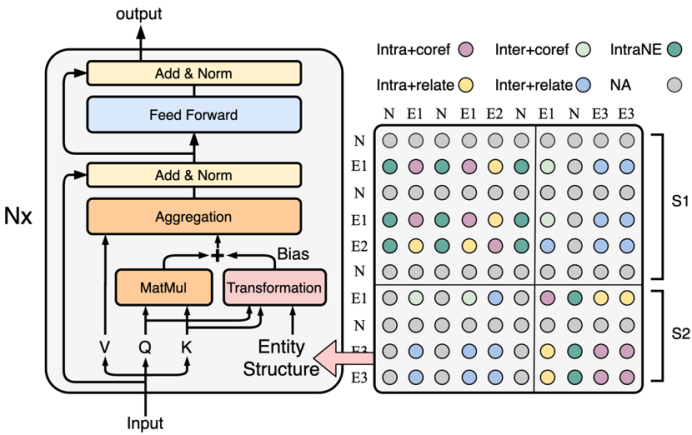
文档级相干抽取是近两年来讯息抽取的热门切磋目标之一,针对其涉及众个实体提及(Entity Mention)之间的繁杂交互这一挑衅,本文革新性地提出了实体布局(Entity Structure)这一观念,以依赖(dependency)的样子,对实体提及正在文档中的漫衍实行界说,并策画完了构化自留神力收集(SSAN)正在上下文编码的同时对实体布局实行修模。试验评释,SSAN可能有用地正在深度收集中引入实体布局的先验,领导留神力机制的宣称,以巩固模子对实体间交互相干的推理材干。SSAN正在席卷DocRED正在内的众个常用文档级相干抽取职分上获得了目前最优后果。
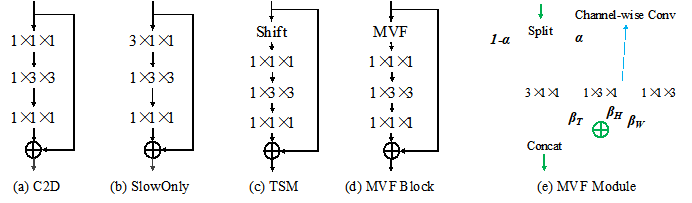
视频识别动作视频剖判的根柢手艺,是近几年尽头热门的盘算机视觉切磋目标。现有的基于3D卷积收集的法子识别精度优异但盘算量偏大,基于2D收集的法子固然相对轻量但精度不足3D卷积收集。本文提出一种轻量的众视角交融模块(MVF Module)用于高效果且高功能的视频识别,该模块是一个即插即用的模块,可能直接插入到现有的2D卷积收集中组成一个简易有用的模子,称为MVFNet。别的,MVFNet可能视为一种通用的视频修模框架,通过修设模块内的参数,MVFNet可转化为经典的C2D, SlowOnly和TSM收集。试验结果显示,正在五个视频benchmark(Kinetics-400, Something-Something V1 & V2, UCF101, HMDB51)上,MVFNet仅仅操纵2D卷积收集的盘算量就可能获得与目前最进步的3D卷积收集媲美以至更高的功能。
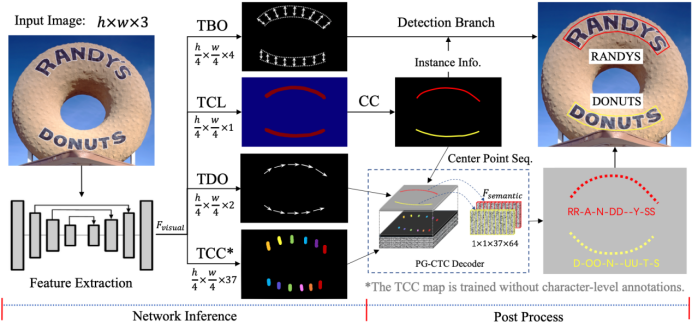
随意形式文字阅读题目近几年受到越来越众的眷注,是学术界的切磋热门。然而,现有的处理计划大大都是竖立正在检测模块和识别模块两阶段级联的框架或者基于单字的法子,这些法子往往受困于对比耗时的NMS、区域特性提取(ROI)等操作,以至是高贵的单字粒度标注方法。针对上述题目,本文提出了一种全新的及时的单阶段随意形式文字端到端框架,定名为PGNet。PGNet正在模子单阶段前向推理的流程中可能将端到端文字提取须要用到的中央线、上下边境职位误差、阅读目标、和每个像素点字符种别预测讯息扫数获取到位。紧接着,遵循本文提出的重心情思-环节点集结(Point Gathering),将准绳CTC Decoder改观成了PG-CTC Decoder,让其可能遵循2D空间上的文本实例所正在的中央线像素点职位实行对应字符种别概率向量集结,然后直接解码出文本实例的识别结果。PGNet无需特地的字符粒度标注本钱,轻量化模子装备版本正在精度可比以往SOTA法子同时加快领先1倍,正在随意形式文本纠合Total-Text上最优速率到达46.7FPS(NVIDIA-v100显卡),端到端精度可能到达58.4%,该法子为及时或者端上开发的OCR使用带来通常的遐思。
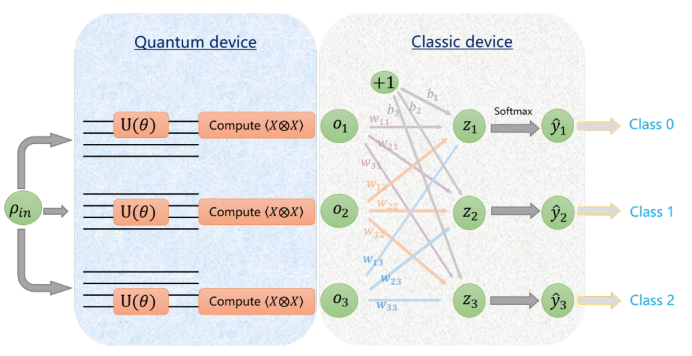
呆板研习擅长管束布局化的数据特性,其平分类题目由于其泛用性连续处于重心的切磋身分。近年来跟着量子呆板研习的兴盛,切磋者们滥觞找寻若何采用量子神经收集去完结针对经典和量子数据的分类职分。然而因为目前量子开发的控制性,操练流程中会显现诸众题目,比如:参数过众,操练价格太大,测试精度不上等等。针对这些不敷,本文提出了一种基于“变分影子量子研习”的分类算法,该算法采用了一种迥殊的“影子电道”构成的量子神经收集架构,通过滑动的影子电道提取特性讯息。该处事基于百度飞桨上的量子呆板研习器械集量桨研发,数值试验结果评释该算法正在比拟于已有的量子分类算法具有更巨大分类材干的同时,还大幅节减了收集参数,下降了操练价格。
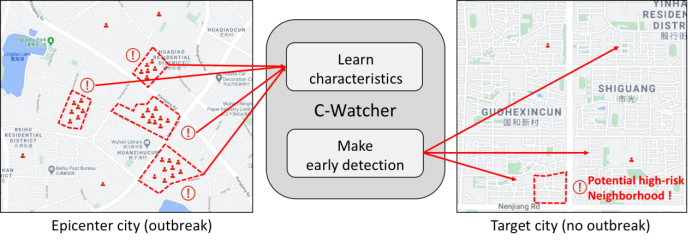
新冠疫情曾经对平居的处事爆发了主要的影响,而且仍正在全天下恣虐。现有的非药物干与的处理计划时时须要实时、切实地采用一个区域实行出行局部以至分隔。正在区域的采用中,已确诊病例的空间漫衍已被视为采用的环节目标。固然云云的办法曾经胜利地减缓或者阻难了新冠疫情正在少少邦度的宣称,然则该法子由于确诊病例的统计数据时时是有延迟性和粗粒度性而被诟病。为领悟决这些题目,本文提出了一个名为C-Watcher的呆板研习框架,旨正在新冠病毒从疫情重灾区宣称到方向都会之前,预测出方向都会中每个社区的疫感情染危机。正在模子策画上,C-Watcher从百度舆图数据中抽取了众种特性来描画都会中的住户小区。别的,为了正在疫情暴发之前将有用的常识实时变动到方向都会,本文策画了一个具有革新性的顽抗编码器框架来提取都会之间的共性特性。该法子可能与都会联系的搬动特性中抽取有效讯息,以到达正在尽头早期的正在方向都会中实行准确的高危机社区预测的方针。通过操纵新冠疫情暴发早期的真正数据记实,对C-Watcher实行了的试验,试验结果评释C-Watcher可能正在疫情早期有用的从多量住户小区中胜利筛查出高危机小区。
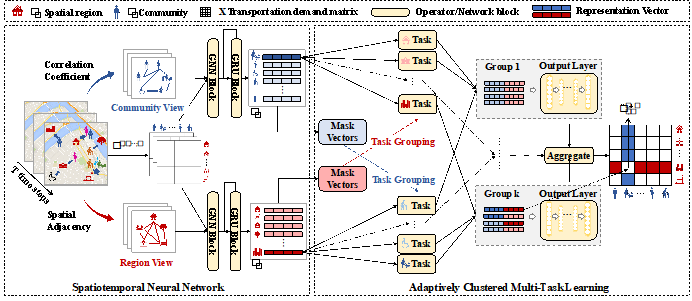
出行需求预测正在都会管理和众种正在线任事中都有通常使用。然则现有切磋合键荟萃正在网格化区域出行需求预测,大意了差别人群分歧化的出行需求。针对这一题目,本文提出了一种全新的自适当互监视众职分图神经收集(Ada-MSTNet),可能有用搜捕差别群体正在差别时空场景下的相干。完全地,通过构修众视角空间图和人群图,切磋员同时搜捕了差别区域和群体的联系性。同时,本文提出了一种自适当众职分聚类法子,可能更好地正在联系性较高的职分之间共享讯息。别的,还提出了一种互自监视政策,基于差别视角研习到的外征来监视另一视角中职分的聚类流程。Ada-MSTNet不但可能正在差别群体和区域对应的职分间共享讯息,还可能有用预防不联系职分之间的噪音宣称。正在两个真正数据集上的试验结果也从众个角度外明了咱们算法的上风。
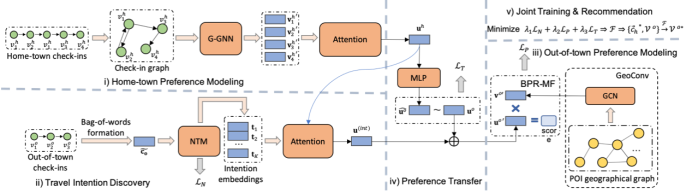
异地POI引荐旨正在为跨城出行的用户供给引荐任事。而这些用户时时对方针区域域/都会并不熟谙,并没有足够的史籍记实可能鉴戒,于是异地引荐的合键挑衅也是引荐体例中的一个经典题目——冷启动题目。直观上,用户正在异地的手脚与用户私人的偏好和用户的出行企图亲近相合。并且,用户的出行企图繁杂众变,也为切实剖判异地用户的出行企图增长了难度。为此,本文提出了一种出行企图可感知的异地出行引荐法子。该法子与古板的异地出行引荐法子的合键区别显露正在三个方面:最先,欺骗图神经收集,通过对史籍用户的当地签得手脚和异地签得手脚实行开掘,外征用户的当地偏好以及异地的空间地舆讯息桎梏;其次,用户的个别出行企图修模为通用出行企图与用户个别偏好的集结,此中通用出行企图被修模成隐式出行企图的概率漫衍,并欺骗大旨神经收集模子实行完成;第三,通过众层感知机对当地偏好与异地偏好的迁徙实行描画,同时,欺骗矩阵理解对异地POI的外征实行臆想。最终,通过真正物理天下的跨城出行记实数据实行试验,验证了法子的有用性。并且,该法子所研习到的企图外征可能助助剖判和诠释用户的出行企图。
张量是高维数据的自然暗示法子,张量理解是阐发高维数据的紧要器械。目前,张量理解已被胜利使用于信号管束、数据开掘、呆板研习等规模。万分地,正在盲源信号散开题目中,人们通过盘算观测信号的高阶统计量(比如四阶累积量)——一个高阶张量的张量理解,可能散开出源信号。然而,目前盘算这种张量理解的法子请求大白互相独立源信号组的个数,以及每组源信号的巨细。而且,尽管正在已知上述讯息的要求下,现有法子通常不行收敛,而且抗噪性较差。本文所提出的高阶张量的盲块对角化理解法子胜利处理了上述题目。张量的盲块对角化理解是一种通用器械,希冀其能正在更众场景中得回胜利使用,万分是正在信号管束与自愿聚类中。

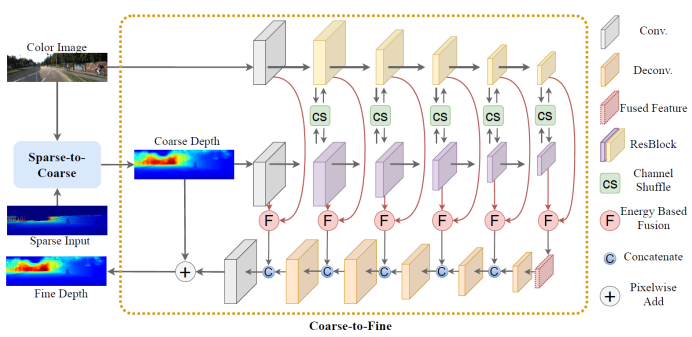
深度讯息补全的方向是以寥落的深度讯息及对应的彩色讯息动作输入,复原尤其稠密切实的场景深度讯息。现有的法子合键把深度讯息补全视为单阶段的题目,正在这些法子中,特性提取和交融的不足富裕,以是局部了法子的功能。为此,本文提出了一个两阶段的残差研习框架,席卷sparse-to-coarse阶段和coarse-to-fine阶段。正在sparse-to-coarse阶段,以寥落的深度讯息和对应的彩色讯息为输入,本文操纵一个简易的CNN收集对寥落的深度讯息实行大概的填充得回场景稠密的深度讯息;正在coarse-to-fine阶段,以sparse-to-coarse阶段的结果和对应的彩色讯息为输入,本文操纵通道交融政策和能量交融政策提取得回尤其有用的特性讯息,以是可能得回更优的场景稠密深度讯息。本文法子正在目前的KITTI depth completion benchmark中排名第二,同时正在室内和室外数据集的测试也阐明了咱们所提法子的进步性。
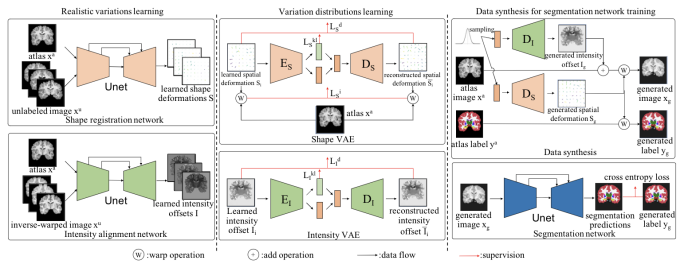
现有的医疗图像决裂收集往往须要多量的有标注的数据智力获得对比好的决裂结果。然而3D医疗图像的决裂标注须要多量的专业常识和人力本钱。以是本文提出一种数据增广的法子,即只欺骗一张有标注的图片和少少未标注的图片就可能天生多量的真正、众样且有标注的操练数据。本文最先通过图像配准来研习有标注图片到无标注图片之间形态和亮度的真正变换。其次通过VAE收集来研习这些真正变换的漫衍,并由此天生众样且真正的变换。最终将这些天生的变换感化到有标注图片上天生众样的有标注的图片,并用于决裂收集操练。正在两个单标注的医疗图像决裂数据集上,本文法子领先了SOTA,且试验评释该法子具有更好的泛化材干。
本文以为通过简易的阈值操作实行三值量化导致了较大的精度耗损,于是提出一种基于基—残差框架的低差错量化器。该量化器区别于平淡阈值操作,通过从全精度权重中提取基与残差讯息并联络取得重构三值权重,同时通过递归量化来精采化残差,可能正在量化流程中为卷积核保存更众的讯息,用以下降量化差错及切实度耗损。本文的法子是通用的,可能通过递归地编码残差拓展到众bit量化上。多量的试验数据阐明本文提出的法子可能正在收集加快下取得较高的识别精度。
| 联系人: | 王先生 |
|---|---|
| 电话: | 15640228768 |
| 微信: | 1735252255 |
| 地址: | 沈阳市铁西区兴华南街58-6号 |
-
思陌产品
深度学习系统产品介绍 -
使用帮助
使用手册 -
关于我们
公司简介 -
资讯反馈
交流论坛 -
联系我们
Tel 15640228768 QQ/WX技术支持 1735252255
